
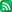
/* rowCache 의 MissRatio를 조사하는 스크립트
** <<박제용 99.11>>
** Row chache 의 Miss ratio는 15% 이하로 유지하는 것이 좋다.
** 그렇지 않을경우 shared_pool_size를 늘리는것을 고려해야 한다.
*/
select sum(gets) "Gets",
sum(getmisses) "Misses",
(1-(sum(getmisses)/(sum(gets)+sum(getmisses))))*100 "HitRate"
from v$rowcache;
/* library Cache Hitratio 출력 스크립트
** <<박제용 99.11>>
** library Cache 의 hitratio 가 0.9 이하이면
** Shared Pool Size를 늘려주거나, SQL 문의 이상을
** 조사해야 한다.
*/
select sum(pins) Executions,
sum(pinhits) "Execution Hits",
sum(reloads) Misses,
((sum(pins) / (sum(pins) + sum(reloads))) * 100) hitratio
from v$librarycache;
/* SQL Cursor를 조사하는 스크립트.
** <<박제용 99.11>>
** SQL Cursor 를 조사하여 부하가 많이 걸리는 SQL문과
** 메모리를 조사한다.
** loads : 캐쉬에서 나갔다 들어온 횟수(best=1).
** invalidations : LRU에서 무효화된 횟수. 이 값이 4이상이면
** shared_pool_area를 확장해야한다.
** parse_calls : 이 커서의 호출 수.
** sorts : 수행된 소트횟수
** command_type: 2 - insert, 3-select, 4-update, 7-delete
*/
select sql_text, loads, invalidations, parse_calls, sorts
FROM v$sqlarea
WHERE sql_text NOT LIKE '%$%'
AND command_type IN(2,3,6,7);
*
** expain plan 결과를 보기 쉽게 출력해주는 스크립트.
**
** 1) expain을 처음 사용할 경우엔 [ORACLE_HOME]/rdbms/admin/utlxplan.sql을 실행,
** plan_table을 생성한다.
** 2) 처음 사용이 아니면 delete from plan_table; 을 실행하여 이전 결과를 삭제.
**
** 실행결과 파싱번호(id)가 길면 SQL이 비효율적이거나, shared_pool_size가 작은것이다.
** 기타 SQL문이 인덱스를 사용하는지 등등을 알수 있다.
*/
col operation format a30
col options format a20
col id format 99
select id, lpad(' ',2*level) || operation ||
decode(id, 0, ' Cost= ' || position )"operation",
options, object_name "object"
from plan_table
connect by prior id=parent_id
start with id =0;
/*
** SQL query 튜닝 스크립트.. <박제용>
**
** 유저별로 과도한 logical read를 수행하는 sql 문 찾기
**
**
*/
Break on User_Name On Disk_Reads on Buffer_Gets on Rows_Processed
Select A.User_Name, B.Disk_Reads, B.Buffer_Gets, B.Rows_Processed, C.SQL_Text
From V$Open_Cursor A, V$SQLArea B, V$SQLText C
Where A.User_Name = Upper('&&User') And A.Address = C.Address
And A.Address = B.Address
Order By A.User_Name, A.Address, C.Piece;
/*
** SQL query 튜닝 스크립트.. <박제용>
**
** 과도한 logical read를 수행하는 SQL문을 V$SQLAREA 에서 검색해줌.
**
** 원인 => 1) 인덱스 컬럼에 distinct한 값이 적은, 부적절한 인덱스의 사용. (대체로 인덱스를 지워야 할 경우)
** 2) 최적화 되지 않은 SQL 문장
*/
select buffer_gets, sql_text from v$sqlarea
where buffer_gets > 200000
order by buffer_gets desc;
/*
** SQL query 튜닝 스크립트.. <박제용>
**
** 과도한 disk read를 수행하는 SQL문을 V$SQLAREA 에서 검색해줌.
**
** 원인 => 1) SQL문이 최적화 되지 않아 disk read를 많이 할 수 밖에 없는 쿼리일경우.
** (index가 없거나 사용되지 않을때)
** 2) db_block_buffers 또는 shared_pool_size 가 작은 경우. (메모리가 적음)
*/
select disk_reads, sql_text from v$sqlarea
where disk_reads > 10000
order by disk_reads desc;
/*
** Shared_pool에 저장된 내용보기 <박제용>
**
** 프로시져나 패키지등은 shared_pool에 저장되며 저장된 객체중
** 그 크기가 100K 가 넘는것을 보여준다.
*/
col name format a30
select name, sharable_mem
from v$db_object_cache
where sharable_mem > 100000
and type in ('PACKAGE', 'PACKAGE BODY', 'FUNCTION', 'PROCEDURE')
and kept = 'NO';
/*
** shared_pool_size의 현재 사용 현황을 보여줌. <박제용>
**
** shared_pool_size의 현재의 사용현황을 보여준다.
** 이 데이터를 주기적으로 보관하여 분석한다.
*/
col value for 999,999,999,999 heading "Shared Pool Size"
col bytes for 999,999,999,999 heading "Free Bytes"
select to_number(v$parameter.value) value, v$sgastat.bytes,
(v$sgastat.bytes/v$parameter.value)*100 "Percent Free"
from v$sgastat, v$parameter
where v$sgastat.name = 'free memory'
and v$ parameter .name = ‘shared_pool_size;
/*
** Shared_pool의 hit ratio보는 스크립트.. <박제용>
**
** 이 영역은 SQL 쿼리문이 저장되고, 유저별 사용 영역과, 데이터 딕셔너리등이 저장된다.
** 만일 적게 할당되면 유저의 접속이 많아질수록 throughput에 큰 영향을 준다.
** hit ratio는 95% 이상을 유지시켜야 한다.
**
*/
select sum(gets) "Gets", sum(getmisses) "Misses",
(1-(sum(getmisses) / (sum(gets)+sum(getmisses))))*100
"HitRate"
from v$rowcache;
/*
** DB의 주요 메모리 사용 조회 <박제용>
**
** DB의 주요 메모리 사용을 보여준다. DB가 사용하는 메모리는
** v7.3의 경우 OS메모리의 2/5 를, v8.x 버젼의 경우 1/2 정도를
** 할당해 주는 것이 좋다.
**
*/
select name, value
from v$parameter
where name in('db_block_buffers','db_block_size','shared_pool_size','sort_area_size');
/*
** DB_BLOCK_BUFFERS의 현재 사용 현황을 보여줌. <박제용>
**
** block_buffer를 튜닝하기 전에 현재의 사용현황을 보여준다.
** 이 데이터를 주기적으로 보관하여 분석한다.
*/
select decode(state, 0, 'FREE',
1, decode(lrba_seq,0,'AVAILABLE','BEING USED'),
3, 'BEING USED', state)
"BLOCK STATUS", count(*)
from x$bh
group by decode(state,0, 'FREE',
1, decode(lrba_seq,0,'AVAILABLE','BEING USED'),
3, 'BEING USED', state);
/*
** DB_BLOCK_BUFFERS의 hit ratio보는 스크립트.. <박제용>
**
** 이 영역은 유저의 쿼리 내용이 버퍼링 되는 공간으로 크기가 적으면
** 유저별로 과도한 disk read를 발생시킨다.
** hit ratio는 90~95% 이상을 유지시켜야 한다.
**
*/
select 1-(sum(decode(name, 'physical reads', value,0))/
(sum(decode(name, 'db block gets', value,0)) +
(sum(decode(name, 'consistent gets', value,0))))) * 100
"Read Hit Ratio"
from v$sysstat;
/*
** 테이블 analyze 스크립트 2.. <박제용>
** 한 유저에 속한 모든 객체를 analyze한다.
**
** 사용방법 SQL>@analyze0 [유저ID]
** 유저ID는 반드시 대문자로.
*/
exec dbms_utility.analyze_schema('&1','DELETE');
exec dbms_utility.analyze_schema('&1','COMPUTE');
/*
** 테이블 analyze 스크립트.. <박제용>
** Query를 파싱하는 Optimizer로 하여금 더욱 정확하고, 빠른 파싱을 유도하기위해 Analyze를 한다.
**
** 사용방법 SQL>@analyze1 [테이블명]
*/
analyze table &1 delete statistics;
analyze table &1 compute statistics;
** trace 결과를 파악을 위한 Tkprof 유틸리티 사용
** TKPROF trace_file output_file [옵션설정] [explain=username/password]
** trace_file SQL_TRACE로 생성한 트레이스 *.trc 트레이스 파일.
** output_file 결과가 저장될 파일명
** SORT=parameters 소팅 파리미터 execpu, ....
** EXPLAIN=username/password
** SYS=no/yes 시스템이 사용한 쿼리를 볼때는 yes로 설정한다.
예제))))
tkprof ora_12626.trc result.txt explain=scott/tiger sys=no
c:\orawin95\bin\tkprof73.exe 2.TRC ORA%1.TXT explain=TUNING/TUNING sys=no sort=execpu
EDIT ORA%1.PRF

Posted by 홍반장

